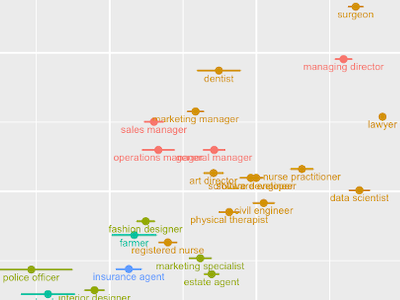
The rise of social media and computational social science (CSS) has opened countless opportunities to explore social science questions with new forms of data and methods. However, CSS research on socioeconomic inequality, a fundamental problem in sociology, has been constrained due to the lack of individual-level socioeconomic status (SES) measures in digital trace data. LSE PhD student Yuanmo He and I propose a new approach to address this problem. Following Bourdieu, we argue that the commercial and entertainment accounts that Twitter users follow reflect their economic and cultural capital and hence, we can use these followings to infer the users’ SES. Inspired by political science approaches to inferring social media users’ political ideology, we develop a method that uses correspondence analysis to project official Twitter accounts and their followers onto a linear SES scale. Using this method, we estimate the SES of 3,482,657 Twitter users who follow the Twitter accounts of 339 supermarkets and department stores, clothing and speciality retailers, chain restaurants, newspapers and news channels, sports, and TV shows in the United States. We validate our estimates with data on audience composition from the Facebook Marketing API, self-reported job titles on users’ Twitter profiles, and a small survey sample. The results show reasonable correlations between our SES estimates and the standard proxies for SES: education, occupational class, and income at the aggregate level and weaker but still significant correlations at the individual level. The proposed method opens new opportunities for innovative social research on inequality on Twitter and similar online platforms.
The paper was published in Sociological Methods and Research.